Google Data Analytics Professional Certificate - Part 4
This is part of a series of posts on the Google Data Analytics course from Coursera. It is not meant to be a review of the course nor by any means an extensive overview of its content. This is intended to be short and incorporate only the main concepts and learnings I gathered from each module. My purpose for these blog posts is mainly to consolidate what I learned from the course and also an attempt to help anyone who might be interested in reading a little bit about these subjects/this course.
In this post you will find a mix of direct content from the course, my own personal notes and also some extrapolations and additions I made wherever I felt the need to add information.
Process Data from Dirty to Clean
Data integrity and analytics objectives
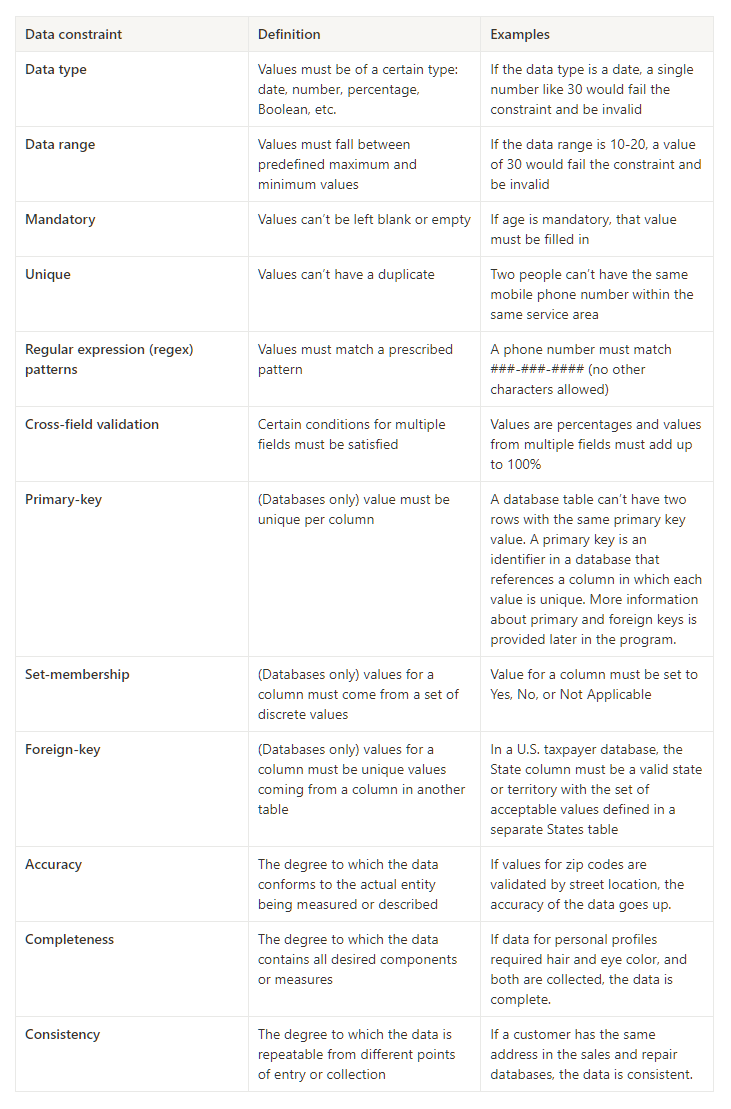
→ The table below offers definitions and examples of data constraint terms you might come across:
Overcoming the challenges of insufficient data
→ Consider the following data issues and suggestions on how to work around them:
- Data Issue 1 - No data
-bc9468d7.png)
- Data Issue 2 - Too Little Data
-e76f8a23.png)
- Data Issue 3 - Wrong Data (including data with errors)
-b6a4fd73.png)
→ Use the following decision tree as a reminder of how to deal with data errors or not enough data:
-4eeb2a8f.png)
Figure from the Google Data Analytics course on Coursera.
→ Some terms and definitions about sampling:
-4c320f65.png)
→ A sample size calculator tells you how many people you need to interview (or things you need to test) to get results that represent the target population. Here are some terms regarding sample size calculators:
Confidence level: The probability that your sample size accurately reflects the greater population.
Margin of error: The maximum amount that the sample results are expected to differ from those of the actual population. More technically, the margin of error defines a range of values below and above the average result for the sample. The average result for the entire population is expected to be within that range. In most cases, a 90% or 95% confidence level is used. But, depending on your industry, you might want to set a stricter confidence level.
Population: This is the total number you hope to pull your sample from.
Sample: A part of a population that is representative of the population.
Estimated response rate: If you are running a survey of individuals, this is the percentage of people you expect will complete your survey out of those who received the survey.
→ When figuring out a sample size, here are things to keep in mind:
Don’t use a sample size less than 30. It has been statistically proven (based on the Central Limit Theorem in the field of probability and statistics) that 30 is the smallest sample size where an average result of a sample starts to represent the average result of a population.
The confidence level most commonly used is 95%, but 90% can work in some cases.
Increase the sample size to meet specific needs of your project: higher confidence level; decrease of the margin of error; greater statistical significance.
Testing your data
→ Sometimes the data to support a business objective isn’t readily available. This is when proxy data is useful. Here are some scenarios and where proxy data comes in for each example:
-e39aedbd.png)
Data cleaning is a must
→ Dirty data is data that contains errors, inconsistencies, or inaccuracies. This can include things like typos, missing values, duplicate entries, and invalid data. Dirty data can also include data that is not in a format that can be easily used or analyzed. It's also called "bad data" or "garbage data". These errors can cause issues when trying to analyze or make decisions based on the data, and so it needs to be cleaned before use. Here are the most common types of dirty data:
-eabeba56.png)
→ Data integrity refers to the accuracy and consistency of data over its entire life-cycle. It ensures that data is accurate, complete, consistent, and reliable. Data integrity is important because it is used to make important decisions and if the data is incorrect, the decision could also be incorrect. Here are the four principles of data integrity:
Validity — the concept of using data integrity principles to ensure measures conform to defined business rules or constraints
Accuracy — the degree of conformity of a measure to a standard or a true value
Completeness — the degree to which all required measures are known
Consistency — the degree to which a set of measures is equivalent across system
→ There are several ways to ensure data integrity, including:
Using constraints and validation rules to ensure that data is entered correctly in the first place;
Regularly checking for and removing duplicate data;
Using backup and recovery procedures to prevent data loss;
Using data encryption to protect data from unauthorized access or tampering;
Auditing and monitoring data access to detect and prevent unauthorized changes;
Regularly validating data by comparing it to a known good source.
Begin cleaning data
→ Common mistakes to avoid:
-12e8957d.png)
→ Questions to ask while checking compatibility:
Do we have all the data we need? -do datasets give me the info to answer business questions/solve a business problem?
Does the data we need exist within these datasets?
Do the datasets need to be cleaned?
Are datasets cleaned to the same standard?
How are missing values handled?
How recently was the data updated?
Using SQL to clean data
→ Regarding the SQL content, both from this module and from later ones, I didn’t take many notes because I have already done Udacity’s course ‘SQL for Data Analysis’, which is a very good course on the topic, and I took an extensive amount of notes from it so I felt no need to do the same here. I do plan on soon writing some blog posts (depending on how long the full content gets) that cover that course.
Manually cleaning data
→ The most common problems of cleaning data manually:
Sources of errors: Did you use the right tools and functions to find the source of the errors in your dataset?
Null data: Did you search for NULLs using conditional formatting and filters?
Misspelled words: Did you locate all misspellings?
Mistyped numbers: Did you double-check that your numeric data has been entered correctly?
Extra spaces and characters: Did you remove any extra spaces or characters using the TRIM function?
Duplicates: Did you remove duplicates in spreadsheets using the Remove Duplicates function or DISTINCT in SQL?
Mismatched data types: Did you check that numeric, date, and string data are typecast correctly?
Messy (inconsistent) strings: Did you make sure that all of your strings are consistent and meaningful?
Messy (inconsistent) date formats: Did you format the dates consistently throughout your dataset?
Misleading variable labels (columns): Did you name your columns meaningfully?
Truncated data: Did you check for truncated or missing data that needs correction?
Business Logic: Did you check that the data makes sense given your knowledge of the business?
Documenting results and the cleaning process
→ A changelog is a document or file that lists the changes made to a software, database, library or any other collection of files. It typically includes a brief description of the changes, the date when the change was made, and the person or team responsible for the change. Changelogs are often used to track the development of a software and to communicate the changes to users, customers, and other stakeholders. They are also used to keep track of bugs and enhancements and to help diagnose issues. Changelogs can be in different forms, such as text files, markdown, html page, or even a part of the software documentation. They can be versioned, have different sections for different types of changes, or have different format based on the organization or the software's use. It should record the following type of information:
Data, file, formula, query, or any other component that changed;
Description of that change;
Date of the change;
A person who made that change;
A person who approved that change;
Version number;
Reason for the change.
→ Best practices for using changelogs:
Changelogs are for humans, so write clear;
Every version should have its own entry;
Each change should have its own line;
Group the same changes;
Versions should be ordered chronologically, latest to newest;
The release date of each version should be noted.
The data analyst hiring process
→ When you take a picture, you usually try to capture lots of different things in one image. Maybe you're taking a picture of the sunset and want to capture the clouds, the tree line and the mountains. Basically, you want a snapshot of that entire moment. You can think of building a resume in the same way. You want your resume to be a snapshot of all that you've done both in school and professionally.
→ When managers and recruiters look at what you've included in your resume, they should be able to tell right away what you can offer their company. The key here is to be brief. Try to keep everything in one page and each description to just a few bullet points. Two to four bullet points is enough but remember to keep your bullet points concise. Sticking to one page will help you stay focused on the details that best reflect who you are or who you want to be professionally. One page might also be all that hiring managers and recruiters have time to look at. They're busy people, so you want to get their attention with your resume as quickly as possible.
→ When it comes to building your resume, templates come in as they're a great way to build a brand new resume or reformat one you already have. Programs like Microsoft Word or Google Docs and even some job search websites all have templates you can use. Here are a few free options I’m familiar with:
Overleaf templates (if you know how to use LaTeX)
About the resume itself:
There's more than one way to build a resume, but most have contact information at the top of the document. This includes:
Name;
Address;
Phone number;
Email address (if you have multiple, use the ones that are most reliable and sound professional).
Some resumes begin with the summary, but this is optional. A summary can be helpful if you have experience that is not traditional for the job you’re applying or if you're making a career transition. If you decide to include a summary, keep it to one or two sentences that highlight your strengths and how you can help the company you're applying to. You'll also want to make sure your summary includes positive words about yourself, like dedicated and proactive. You can support those words with data, like the number of years you've worked or the tools you're experienced in like SQL and spreadsheets.
Try to describe the work you did in a way that relates to the position you're applying for. Most job descriptions have minimum qualifications or requirements listed. These are the experiences, skills, and education you'll need to be considered for the job. It's important to clearly state them in your resume. If you're a good match, the next step is checking out preferred qualifications, which lots of job descriptions also include. These aren't required, but every additional qualification you match makes you a more competitive candidate for the role. Including any part of your skills and experience that matches a job description will help your resume rise above the competition.
It's helpful to describe your skills and qualifications in the same way. For example, if a listing talks about organization and partnering with others, try to think about relevant experiences you've had. In your descriptions, you want to highlight the impact you've had in your role, as well as the impact the role had on you. If you helped a business get started or reach new heights, talk about that experience and how you played a part in it.
If you used data analytics in any of your jobs, one way to include it is to follow a formula in your descriptions: Accomplished X as measured by Y, by doing Z. If you've gained new skills in one of your experiences, be sure to highlight them all and how they helped.
Understand the elements of a data analyst resume
→ Here we’ll see how to refine a resume for data analytics jobs. For data analytics, one of the most important things your resume should do is show that you are a clear communicator. Companies looking for analysts want to know that the people they hire can do the analysis, but also can explain it to any audience in a clear and direct way. Your first audience as a data analyst will most likely be hiring managers and recruiters. Being direct and coherent in your resume will go a long way with them as well.
→ While you won't go into too much detail in the summary section about any work experiences, it's a good spot to point out if you're transitioning into a new career role. You might add something like, "transitioning from a career in the auto industry and seeking a full-time role in the field of data analytics." One strategy you can use are PAR statements. PAR stands for Problem, Action, Result. This is a great way to help you write clearly and concisely. Instead of saying something like, "was responsible for writing two blogs a month," you'd say, "earned little-known website over 2,000 new clicks through strategic blogging." The website being little-known is the problem. The strategic action is the strategic blogging. And the result is the 2,000 new clicks. Adding PAR statements to your job descriptions or skill section can help with the organization and consistency in your resume.
→ Also make sure you include any skills and qualifications you've acquired so far. You don't need to be super technical. But talking about your experience with spreadsheets, Python, SQL, Tableau, and R, will enhance your resume and your chances of getting a job. But definitely keep in mind that you want your resume to accurately represent your skills and abilities.
Highlighting experiences on resume
→ Common professional skills for entry-level data analysts:
1. Structured Query Language (SQL): SQL is considered a basic skill that is pivotal to any entry-level data analyst position. SQL helps you communicate with databases, and more specifically, it is designed to help you retrieve information from databases. Every month, thousands of data analyst jobs posted require SQL, and knowing how to use SQL remains one of the most common job functions of a data analyst.
2. Spreadsheets: Although SQL is popular, 62% of companies still prefer to use spreadsheets for their data insights. When getting your first job as a data analyst, the first version of your database might be in spreadsheet form, which is still a powerful tool for reporting or even presenting data sets. So, it is important for you to be familiar with using spreadsheets for your data insights.
3. Data visualization tools: Data visualization tools help to simplify complex data and enable the data to be visually understood. After gathering and analyzing data, data analysts are tasked with presenting their findings and making that information simple to grasp. Common tools that are used in data analysis include Tableau, Microstrategy, Data Studio, Looker, Datarama, Microsoft Power BI, and many more. Among these, Tableau is best known for its ease of use, so it is a must-have for beginner data analysts. Also, studies show that data analysis jobs requiring Tableau are expected to grow about 34.9% over the next decade.
4. R or Python programming: Since only less than a third of entry-level data analyst positions require knowledge of Python or R, you don’t need to be proficient in programming languages as an entry-level data analyst. But, R or Python are great additions to have as you become more advanced in your career.
→ Common soft skills for an entry-level data analyst resume:
1. Presentation skills: Although gathering and analyzing data is a big part of the job, presenting your findings in a clear and simple way is just as important. You will want to structure your findings in a way that allows your audience to know exactly what conclusions they are supposed to draw.
2. Collaboration: As a data analyst, you will be asked to work with lots of teams and stakeholders—sometimes internal or external—and your ability to share ideas, insights, and criticisms will be crucial. It is important that you and your team—which might consist of engineers and researchers—do your best to get the job done.
3. Communication: Data analysts must communicate effectively to obtain the data that they need. It is also important that you are able to work and clearly communicate with teams and business leaders in a language that they understand.
4. Research: As a data analyst, even if you have all of the data at your disposal, you still need to analyze it and draw crucial insights from it. To analyze the data and draw conclusions, you will need to conduct research to stay in-line with industry trends.
5. Problem-solving skills: Problem-solving is a big part of a data analyst’s job, and you will encounter times when there are errors in databases, code, or even the capturing of data. You will have to adapt and think outside the box to find alternative solutions to these problems.
6. Adaptability: In the ever-changing world of data, you have to be adaptable and flexible. As a data analyst, you will be working across multiple teams with different levels of needs and knowledge, which requires you to adjust to different teams, knowledge levels, and stakeholders.
7. Attention to detail: A single line of incorrect code can throw everything off, so paying attention to detail is critical for a data analyst. When it comes to understanding and reporting findings, it helps if you focus on the details that matter to your audience.
Best practices for writing about experience
→ One of the most important functions of a resume is communicating your prior work experience in a favorable light. This can often be challenging, as the one-page format forces job seekers to summarize all of their work experience into a few bullet points. Resume best practices will help you select the most relevant parts of your work experience and communicate them in the shortest, most impactful way possible. As you think about how to represent your work experience on your resume effectively, it might be helpful to refer to these best practices:
Focus on your accomplishments first, and explain them using the formula “Accomplished X, as measured by Y, by doing Z.”
These statements help you communicate the most important things a recruiter or hiring manager is searching for—the impact of your work.
Whenever possible, use numbers to explain your accomplishments. For example, “Increased manufacturing productivity by 15% by improving shop floor employee engagement,” is better than “Increased manufacturing productivity.”
Phrase your work experience and duties using Problem-Action-Result (PAR) statements.
- For example, instead of saying “was responsible for two blogs a month,” phrase it as “earned little-known website over 2,000 new clicks through strategic blogging.”
Describe jobs that highlight transferable skills (those skills that can transfer from one job or industry to another).
This is especially important if you are transitioning from another industry into data analytics.
For example, communication is a skill often used in job descriptions for data analysts, so highlight examples from your work experience that demonstrate your ability to communicate effectively.
Showing is always more effective than telling.
These are non-technical traits and behaviors that relate to how you work.
Are you detail-oriented? Do you have grit and perseverance? Are you a strong critical thinker? Do you have leadership skills?
For instance, you could give an example of when you demonstrated leadership on the job.
That’s it for the fourth part of the Google Data Analytics course from Coursera. You can also read the previous parts (first, second and third) of the course and soon I’ll be posting the following parts of the course. I also intend to write some more posts on other courses I took (SQL and Python so far), some detailed notes I took (and continue to take) from subjects like data visualisation and probably some short book summaries of my favourite books, with the best quotes and key concepts.
As I mentioned in the beginning, this is mainly with the goal of consolidating all topics I’m interested in learning and also having all of it well structured and put together in one place (this website). So if you find this kind of content useful and wish to read some more, you can follow me on Medium just so you know whenever I post more stuff.