Google Data Analytics Professional Certificate - Part 3
This is part of a series of posts on the Google Data Analytics course from Coursera. It is not meant to be a review of the course nor by any means an extensive overview of its content. This is intended to be short and incorporate only the main concepts and learnings I gathered from each module. My purpose for these blog posts is mainly to consolidate what I learned from the course and also an attempt to help anyone who might be interested in reading a little bit about these subjects/this course.
In this post you will find a mix of direct content from the course, my own personal notes and also some extrapolations and additions I made wherever I felt the need to add information.
Prepare Data for Exploration
Collecting data
Here are some data-collection considerations to keep in mind for your analysis:
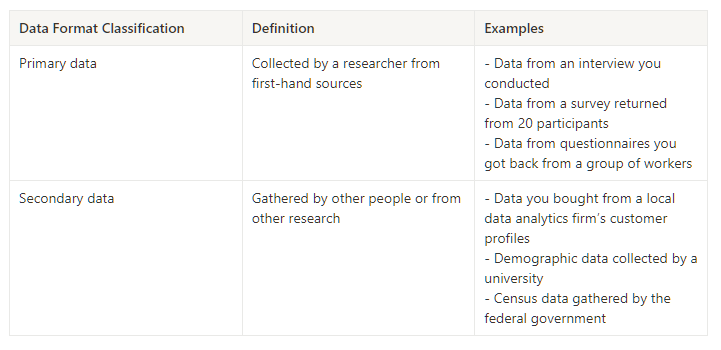
How the data will be collected: Decide if you will collect the data using your own resources or receive (and possibly purchase it) from another party. Data that you collect yourself is called first-party data.
Data sources: If you don’t collect the data using your own resources, you might get data from second-party or third-party data providers. **Second-party data** is collected directly by another group and then sold. **Third-party data** is sold by a provider that didn’t collect the data themselves. Third-party data might come from a number of different sources.
Solving your business problem: Datasets can show a lot of interesting information. But be sure to choose data that can actually help solve your problem question. For example, if you are analyzing trends over time, make sure you use time series data — in other words, data that includes dates.
How much data to collect: If you are collecting your own data, make reasonable decisions about sample size. A random sample from existing data might be fine for some projects. Other projects might need more strategic data collection to focus on certain criteria. Each project has its own needs.
Time frame: If you are collecting your own data, decide how long you will need to collect it, especially if you are tracking trends over a long period of time. If you need an immediate answer, you might not have time to collect new data. In this case, you would need to use historical data that already exists.
.png)
Figure from the Google Data Analytics course on Coursera.
Differentiate between data formats and structures
Common data formats:
Qualitative — listed as a name, category, and description; cannot be counted, measured, or easily expressed using numbers;
Quantitative — expressed as a number; data with quantity, amount, or range;
Discrete — data that are counted and have a limited number of values;
Continuous — can be measured using a timer, and its value can be shown as a decimal with several places;
Nominal — a type of qualitative data that’s categorized without a set order; it doesn’t have a sequence (yes, no, not sure responses);
Ordinal — type of qualitative data with a set of order or a scale (rank a movie from 1 to 5);
Internal — data from a company’s own system; more reliable and easier to collect;
External — data that lives and it’s generated outside of the organization, useful when analysis depends on as many sources as possible, they are usually structured;
Structured — organized in a certain format (spreadsheets and relational databases);
Unstructured — not organized in any easily identifiable manner (audio and video files).
→ Primary vs Secondary data:
→ Internal vs External data:
-9412463f.png)
→ Continuous vs Discrete data:
-301fd513.png)
→ Qualitative vs Quantitative data:
-6f4a4251.png)
→ Nominal vs Ordinal data:
-22c3c6b6.png)
→ Structured vs Unstructured data:
-99050bbe.png)
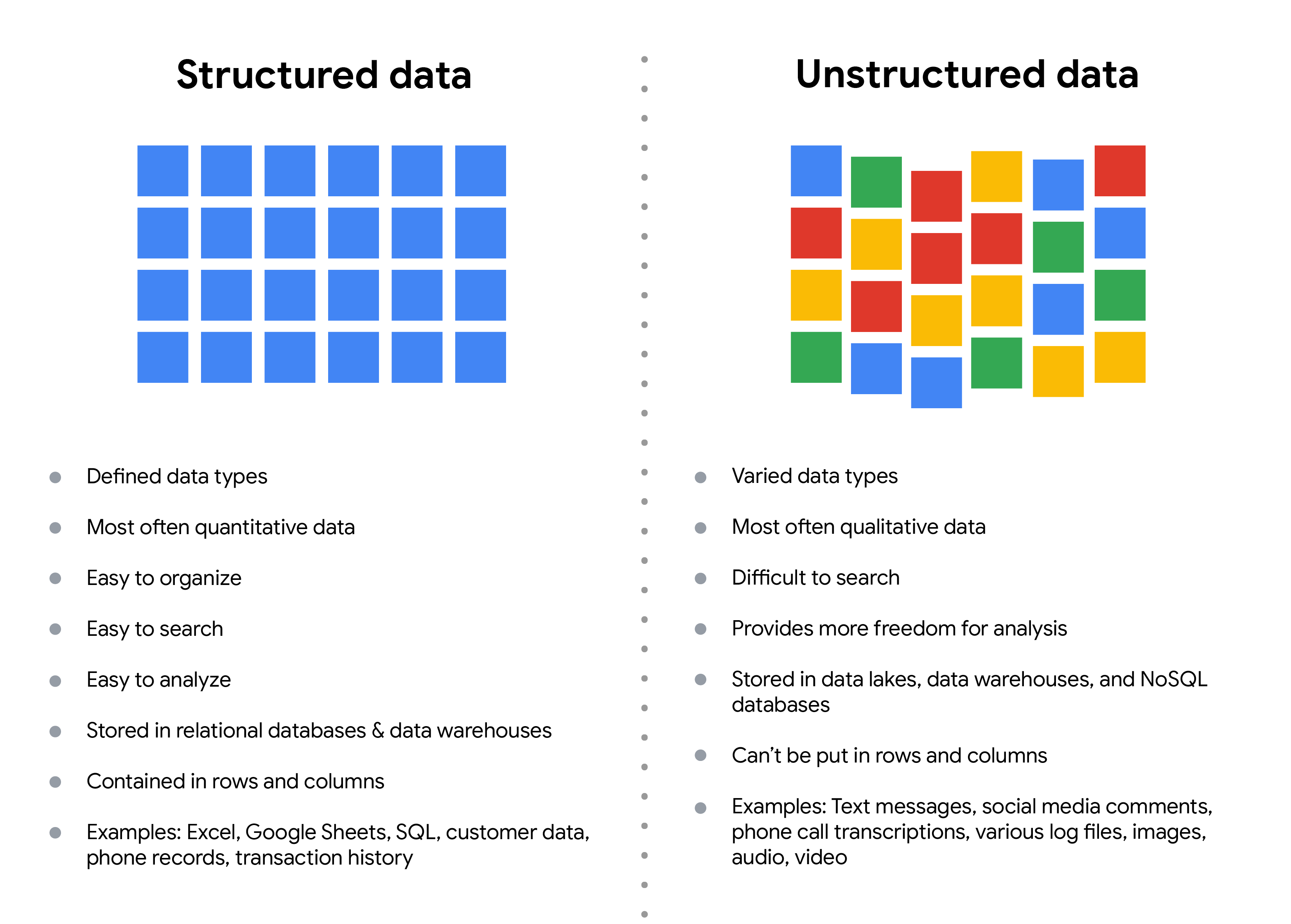
Figure from the Google Data Analytics course on Coursera.
→ Wide vs Long Data:
The terms "wide" and "long" data are used to describe the format of data sets in statistics and data analysis. The main difference between wide and long data is the way the variables are organized in the data set.
In wide data, every data subject has a single row with multiple columns to hold the values of various attributes of the subject (to be used when there are few variables about each subject, comparing straightforward line graphs). In long data each row is a one-time point per subject, so each subject will have data in multiple rows (to be used for storing and organizing data when there are multiple variables for each subject).
Data modeling
→ Data modeling is the process of creating diagrams that visually represent how data is organized and structured. These visual representations are called data models. You can think of data modeling as a blueprint of a house. At any point, there might be electricians, carpenters, and plumbers using that blueprint. Each one of these builders has a different relationship to the blueprint, but they all need it to understand the overall structure of the house. Data models are similar; different users might have different data needs, but the data model gives them an understanding of the structure as a whole. Each level of data modeling has a different level of detail.
-d0eeec02.png)
Figure from the Google Data Analytics course on Coursera.
Conceptual data modeling gives a high-level view of the data structure, such as how data interacts across an organization. For example, a conceptual data model may be used to define the business requirements for a new database. A conceptual data model doesn't contain technical details.
Logical data modeling focuses on the technical details of a database such as relationships, attributes, and entities. For example, a logical data model defines how individual records are uniquely identified in a database. But it doesn't spell out actual names of database tables. That's the job of a physical data model.
Physical data modeling depicts how a database operates. A physical data model defines all entities and attributes used; for example, it includes table names, column names, and data types for the database.
Explore data types, fields, and values
→ Below are Venn diagrams that illustrate the Boolean logic. AND is the center of the Venn diagram, where two conditions overlap. OR includes either condition. NOT includes only the part of the Venn diagram that doesn't contain the exception.
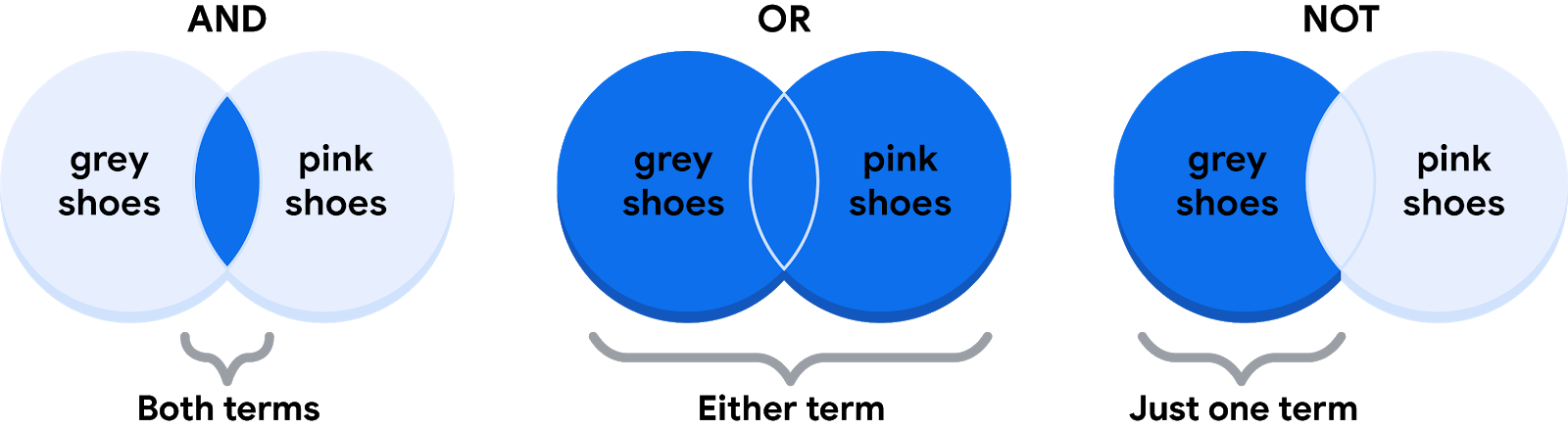
Figure from the Google Data Analytics course on Coursera.
- The AND operator
→ Below is a simple truth table that outlines the Boolean logic at work in this statement. In the Color is Grey column, there are two pairs of shoes that meet the color condition. And in the Color is Pink column, there are two pairs that meet that condition. But in the If Grey AND Pink column, there is only one pair of shoes that meets both conditions. So, according to the Boolean logic of the statement, there is only one pair marked true.
-64faa4d4.png)
- The OR operator
→ Notice that any shoe that meets either the Color is Grey or the Color is Pink condition is marked as true by the Boolean logic. According to the truth table below, there are three pairs of shoes that you can buy.
-8c9087e5.png)
- The NOT operator
→ Now, all of the grey shoes that aren't pink are marked true by the Boolean logic for the NOT Pink condition. The pink shoes are marked false by the Boolean logic for the NOT Pink condition. Only one pair of shoes is excluded in the truth table below.
.png)
Data transformation
→ Data transformation usually involves:
Adding, copying, or replicating data;
Deleting fields or records;
Standardizing the names of variables;
Renaming, moving, or combining columns in a database;
Joining one set of data with another;
Saving a file in a different format (saving a spreadsheet as a CSV file).
→ Goals for data transformation might be:
Data organization: better organized data is easier to use;
Data compatibility: different applications or systems can then use the same data;
Data migration: data with matching formats can be moved from one system to another;
Data merging: data with the same organization can be merged together;
Data enhancement: data can be displayed with more detailed fields;
Data comparison: apples-to-apples comparisons of the data can then be made.
Unbiased and objective data
→ A bias is a preference in favor of or against a person, group, or thing. And a data bias is a type of error that systematically skew the result, like having an influence on answers, or a sample group that’s not representative. Types of biases in data:
Sampling bias — when a sample isn’t representative, for example, not inclusive;
Observer bias — the tendency for different people to observe things differently;
Interpretation bias — same thing interpreted in a different way by a different person;
Confirmation bias — tendency to search for or interpret information in a way that confirms preexisting beliefs.
Explore data credibility
→ ROCCC is a process used to ensure a credibility with the following aspects:
Reliable — data must be accurate, complete, and unbiased;
Original — data must be validated with the original source;
Comprehensive — data must contain all critical information;
Current — data must be current and relevant to the task at hand;
Cited — citing makes the info you’re provided more credible.
Data ethics and privacy
→ Ethics are well-founded standards of right and wrong that prescribe what humans should do. Data ethics are standards of right and wrong that dictate how data is collected, shared, and used. The six main aspects of data ethics are:
Ownership — who owns the data; individuals who own raw data, not organizations who collect it;
Transaction transparency — all data processing activities and algorithms should be completely explainable and understood by the individual who provides that data;
Consent — individual’s right to know explicit details about how and why their data will be used before agreeing to provide it;
Currency — individuals should be aware of the financial transactions resulting from the use of their personal data and the scale of these transactions;
Privacy and protection — preserving a data subject’s information and activity any time a data transaction occurs. It’s about access, use, and collection of data;
Openness — free access, usage, and sharing of data.
→ Data privacy implies person’s legal rights to their data. This means:
Protection from unauthorized access;
Freedom from inappropriate use;
The right to inspect, update and correct our data;
Ability to give consent for using data;
Legal rights to access our data.
Understanding open data
→ In data analytics, open data is part of data ethics, which has to do with using data ethically. Openness refers to free access, usage, and sharing of data. But for data to be considered open, it has to:
Be available and accessible to the public as a complete dataset
Be provided under terms that allow it to be reused and redistributed
Allow universal participation so that anyone can use, reuse, and redistribute the data
→ The 3 principles of openness of data:
Free access, usage, and sharing of data — open data must be available as a whole, usually by downloading over the internet;
Reuse and distribution — open data must be provided under terms that allow reuse and redistribution;
Interoperability — the ability of data systems and services to openly connect and share data.
Managing data with metadata
→ Metadata is data that describes other data. It provides information about a particular item's content, including characteristics such as its author, creation date, and file format. This information can be used to organize, search, and manage the data. In the context of digital data, metadata is often embedded in the file or otherwise associated with the item. It can be used by software and systems to understand and process the data, as well as by people to understand the content and context of the item. In data analytics, metadata is used in DB management to help analysts interpret the contents of the data within the database. The following are elements of metadata:
Title and description;
Tags and categories;
Who created it and when (author and time);
Who last modified it and when;
Who can access or update it (authorization).
→ The 3 types of metadata:
Descriptive — describes a piece of data and can be used to identify it at a later point in time (ISBN on books);
Structural — indicates how a piece of data is organized and whether it’s a part of one or more data collection; how pages of a book are put together to create different chapters; structural metadata keeps track of the relationships between two things;
Administrative — indicates the technical source of a digital asset; metadata in the photo is administrative metadata.
→ Some examples of metadata:
In photos — camera filename, date, time, geolocation
At emails — subject line, sender, recipient, date, and time sent. hidden metadata in emails — server names, IP, HTML format, and software details
In spreadsheets and docs — titles, author, creation date, number of pages, use comments, names of tabs, tables, and columns
In websites — tags and categories, site creator’s name, webpage title and description, time of creation, and iconography
In digital files — file name, size, type, date of creation, and modification
In books — title, author’s name, a table of contents, publisher info, copyright, index, a brief description of the book contents
Effectively organise data
→ Some recommendations and best practices for naming files:
Work out and agree on file naming conventions early on in a project to avoid renaming files again and again;
Align your file naming with your team's or company's existing file-naming conventions;
Ensure that your file names are meaningful; consider including information like project name and anything else that will help you quickly identify (and use) the file for the right purpose;
Include the date and version number in file names; common formats are YYYYMMDD for dates and v## for versions (or revisions);
Create a text file as a sample file with content that describes (breaks down) the file naming convention and a file name that applies it;
Avoid spaces and special characters in file names, instead, use dashes, underscores, or capital letters; spaces and special characters can cause errors in some applications.
→ Best practices for keeping files organized:
Create folders and subfolders in a logical hierarchy so related files are stored together;
Separate ongoing from completed work so your current project files are easier to find; archive older files in a separate folder, or in an external storage location;
If your files aren't automatically backed up, manually back them up often to avoid losing important work.
Securing data
→ Data security refers to the protection of data from unauthorized access, use, disclosure, disruption, modification, or destruction. It is a multi-disciplinary field that includes various technologies, processes and policies to secure data in various forms, such as in databases, networks, cloud systems, and physical devices. Data security is important to prevent unauthorized access to sensitive information, to maintain the integrity of the data, and to ensure the availability of the data to authorized users.
→ There are several ways to secure data, including:
Access control: This is the process of limiting access to data based on user identities and roles. This can include methods such as user IDs and passwords, two-factor authentication, and biometric identification.
Data encryption: This is the process of encoding data so that it is unreadable by unauthorized parties. This can include methods such as symmetric encryption and asymmetric encryption, using unique algorithms to alter data and make it unusable by users and applications that don’t know the algorithm. This algorithm is saved as a “key” which can be used to reverse the encryption; so if you have the key, you can still use the data in its original form;
Tokenization: This replaces the data elements you want to protect with randomly generated data referred to as a “token.” The original data is stored in a separate location and mapped to the tokens. To access the complete original data, the user or application needs to have permission to use the tokenized data and the token mapping. This means that even if the tokenized data is hacked, the original data is still safe and secure in a separate location;
Network security: This is the process of protecting data as it travels over a network. This can include methods such as firewalls, intrusion detection and prevention systems, and virtual private networks (VPNs).
Data backup and recovery: This is the process of creating and maintaining copies of data to protect against data loss. This can include methods such as regularly backing up data to an external hard drive, cloud storage, or a remote server.
Physical security: This is the process of protecting data from physical threats, such as theft, fire, and natural disasters. This can include methods such as locking servers and storage devices in a secure location and using surveillance cameras to monitor access to the facility.
→ It's also important to keep in mind that data security is not only a technical problem but also a organizational problem. Having a strong security policies, compliance regulations and employee awareness training would enhance the overall data security.
Create or enhance your online presence
→ A professional online presence can:
Help potential employers find you;
Help us make connections with other analysts;
Easily learn and share data findings;
Participate in community events.
Build a data analytics network
→ Most common networks for data analysts:
LinkedIn — it helps us make connections, follow industry standards and to find job opportunities. It became the standard proffesional social media site and it’s a good starting place for building online presence.
GitHub — must have account for anyone working in IT. It helps us share insight and resources, read forums and wikis, even to manage team projects. Also it’s a great way to store and show your work to recruiters.
Kaggle — an online community platform for data analysts, data scientists and machine learning enthusiasts. It offers Jupyter Notebooks environment, public datasets, free courses and competitions.
That’s it for the third part of the Google Data Analytics course from Coursera. You can also read the previous parts (first and second) of the course and soon I’ll be posting the following parts of the course. I also intend to write some more posts on other courses I took (SQL and Python so far), some detailed notes I took (and continue to take) from subjects like data visualisation and probably some short book summaries of my favourite books, with the best quotes and key concepts.
As I mentioned in the beginning, this is mainly with the goal of consolidating all topics I’m interested in learning and also having all of it well structured and put together in one place (this website). So if you find this kind of content useful and wish to read some more, you can follow me on Medium just so you know whenever I post more stuff.